Monday, August 04, 2014
Friday, January 20, 2012
Database.com
- interesting to see how many of the features (value and display lists, row id references) are similar to (for example) Caché 's: basically nothing is ever new in computing it seems
- its usability would be greatly increased I guess if it supported disconnected recordsets so that a client application can use it even without access to the cloud
More soon.
Wednesday, January 12, 2011
Yahoo + Koprol != Love

You would think that it would be easy to link your Yahoo and Koprol accounts.
If only.
Thursday, January 06, 2011
Running Cache on a Linux VM
• Login: vmplanet
• Pass: vmplanet.net
• RootPass: vmplanet.net
Download the SUSE Cache install from InterSystems.
Install is rather easy with the RPM sw management system on SUSE.
Set the network connection on the VM to "Bridged" to allow the VM to use the host's network.
The ports have to be enabled on the Linux VM:
su root
iptables -F INPUT (Delete all the INPUT rules)
iptables -P INPUT ACCEPT
To enable remote access from the Cache toolset:
• port: 1972
• web port: 57772
• login: ... the usual, _system or SuperUser
To connect from Terminal:
• enable telnet service on VM
• create a .session.sh script to launch Cache session, chmod +x
Cache must already be running (su ccontrol start cache if it is not)
• in .profile for vmplanet user add line to invoke session.sh
More useful appliances.
Studio connected to Cache running on a SUSE VM:

A view from the Linux VM:

Remote terminal connection:

Sunday, September 26, 2010
Caché Data Access Modes
Below is a routine called TestModes.mac, invoked by a >do ^TestModes. The SQLCompile macro is necessary because the SQL code references objects which do not exist compile time, before CreateTable is run (InsertData). The multi-dimensional sparse arrays created as SQL tables (by CreateTable) are accessed in multi-value mode by ReadMV and deleted by DropMV (which also uses the DeleteExtent method of the data objects to perform a ‘table truncation’ on the data objects).
Another nice feature is the extraction of the list items from the arrays (table data rows are stored as array items, whereby each field is stored in a string list created by $LISTBUILD) back to strings by the $LISTTOSTRING function.
Some legacy features are visible (the need to declare SQLCODE as a public variable and make it NEW to restrict it to the current scope). I don’t think that this kind of mix would make sense in an application, where it would make sense to use one access metaphor and only one for a given data item; but this is still a valuable example which ties the data architecture(s) of Caché together nicely.
TestModes
; shows the different data access types
; SQL, MV, class
#SQLCompile Mode = DEFERRED
DO CreateTable
DO InsertData(1000)
DO ReadMV
DO DropMV
WRITE $$ReadData()
QUIT
;
CreateTable()
{
&sql( DROP TABLE items)
&sql( CREATE TABLE items(id INT, data VARCHAR(50)))
QUIT
}
InsertData(upto)[SQLCODE]
{
#DIM x as %String
#DIM i as %Integer
NEW SQLCODE
FOR i = 1:1:upto
{
SET x = i _ " DataItem"
&sql( INSERT INTO SQLUser.items(id, data) VALUES( :i, :x))
IF (SQLCODE '= 0 )
{
WRITE "SQL error:", $ZERROR, !
}
}
QUIT
}
ReadMV()
{
#DIM ky AS %String
#DIM extr AS %String
WRITE "Navigating the data", !
SET ky = $ORDER(^User.itemsD(""))
WHILE( ky '= "")
{
; WRITE ky, ^User.itemsD(ky), !
SET ky = $ORDER(^User.itemsD(ky))
IF ( ky '= "" )
{
SET extr = $LISTTOSTRING(^User.itemsD(ky))
WRITE ?5, extr, !
}
}
QUIT
}
DropMV()
{
DO ##class(User.items).%DeleteExtent()
KILL ^User.itemsD
QUIT
}
ReadData() [SQLCODE]
{
#Dim result AS %String
NEW SQLCODE
&sql(SELECT COUNT(*) INTO :result FROM SQLUser.items )
; the table is still there, but empty
IF (SQLCODE '= 0) SET result = "Error " _ $ZERROR
Q result
}
Tuesday, June 29, 2010
MySQL and SQL Server
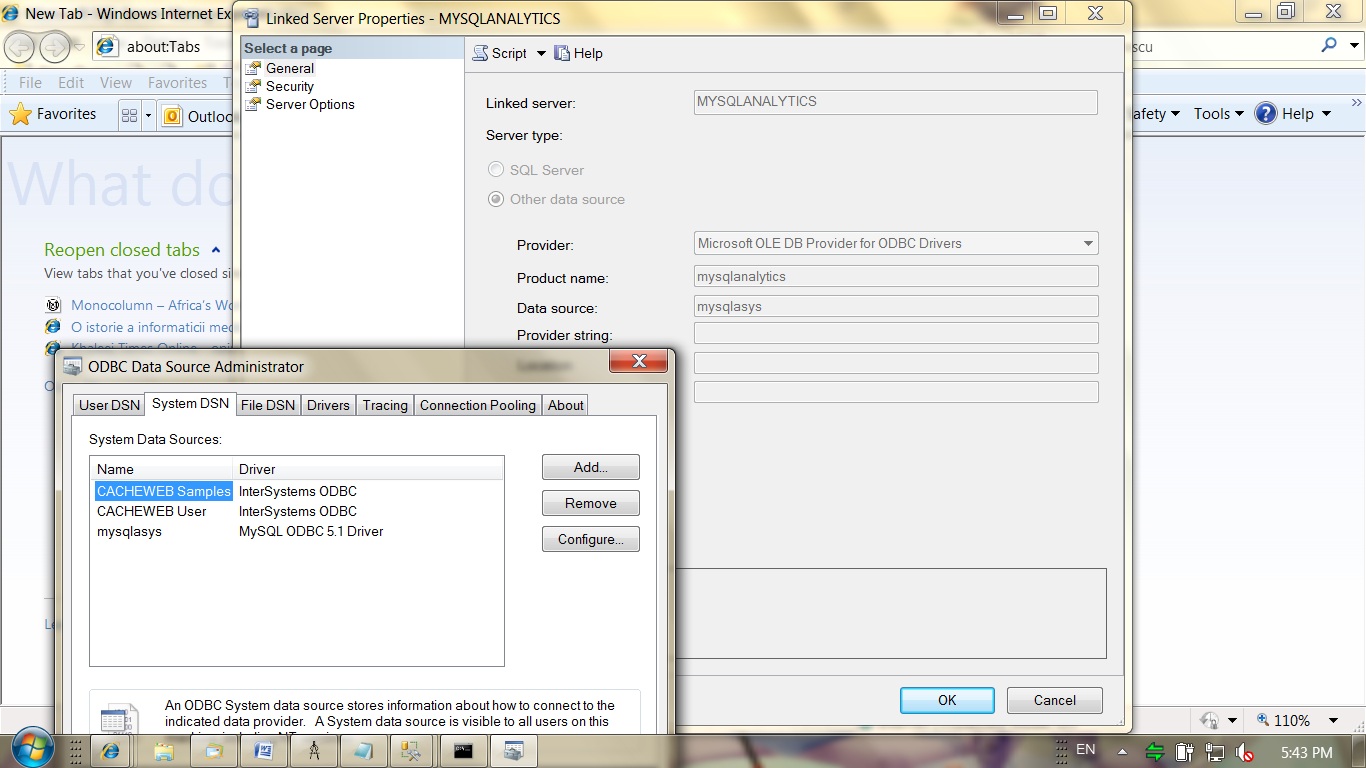
To query (from SQL Server):
select top 5 * from mysqlanalytics...analytics;
select * from mysqlanalytics...session;
mysql> create view ViewSession as
-> select GetSession() as CurrentSession;
Query OK, 0 rows affected (0.06 sec)
mysql> select * from viewsession;
+----------------+
CurrentSession
+----------------+
1
+----------------+
select * from mysqlanalytics...ViewSession
Friday, June 25, 2010
Wednesday, June 16, 2010
Monday, June 14, 2010
Wednesday, June 09, 2010
CMS everywhere
That being said, there are conceptual differences - Zope is middleware-centric (the database is customized for it), Django is database-centric (you start with the db definition, even if it is done at the ORM level: you start with the classes in Python which then get mapped to relational tables) and ASP.MVC is purely database centric (using LINQ to SQL - the classes are generated from the relational tables).
Finally you have something like eZ Publish where objects exist somewhere between PHP and the CMS, and are stored in a bit bucket (relational database, but with no relational features per se, so they might be better off using Mongo or Cache for speed).
Other than that, same features - URL mapping, templates, etc.
Next, I'll delve into ZODB, it would be interesting to see how much is actually stored there and how much in /var.
Speaking of ASP.MVC, here are a couple of links on SEO, relevant to other CMS as well (especially to migrations!):
Tuesday, June 08, 2010
Python classes
Old-style:
class OldClass:
def method(self):
….
Characterized by:
P = OlcClass()
p.__class__ à 'OldClass'
type(p) à 'instance'
>>> class Test:
def __init__(self):
print 'Test initialized'
def meth(self):
self.member = 1
print 'Test.member = ' + str(self.member)
>>> class TestKid(Test):
"This is derived from Kid, meth is overriden and so is member"
def __init__(self):
print 'Kid initialized'
def meth(self):
self.member = 2
Test.meth(self)
print 'Kid.member = ' + str(self.member)
Above is shown how to override a method, call its parent implementation; the member attribute is shared between the parent and child classes and hence calling a function in parent which references it will modify it in the child as well. The parent constructor (or any other overridden function) is not called by default.
New-style:
>>> class Test(object):
Type(p) would return 'Test'. Unifies types and classes.
It has classmethods and staticmethods.
Also (for both old and new):
P = Test() ; calling a class object yields a class instance
p.__dict__ à {'member':1}
p.__dict__['member'] = 1 ; same as p.member
You can use properties (almost .NET-style) to access class attributes with new classes.
More.
Thursday, May 27, 2010
Images in SQL Server
In T-SQL:
update version set [file] = BulkColumn from
openrowset(bulk 'e:\....jpg', single_blob) as [file]
where ...;
In Python/MySQL, this is done like this: (the image column, image_data, is defined as BLOB in MySQL)
>>> import MySQLdb
>>> connection = MySQLdb.connect('','root','','RTest')
>>> blob = open('d:\\pic1.jpg', 'rb').read()
>>> sql = 'INSERT INTO rtest.mm_image(image_data, mm_person_id_mm_person) VALUES(%s, 1)'
>>> args = (blob,)
>>> cursor = connection.cursor()
>>> cursor.execute(sql, args)
>>> connection.commit()
blob is a string type.
Wednesday, May 26, 2010
CMSRDBMSWT..?
Speaking of CMS: Here's Plone, which is running on a NoSQL incidentally.
Thursday, May 20, 2010
Python ORM
The second, improved shot. Inheritance/polymorphism in weakly-typed languages such as Python is a bit hard to grasp at first. Anyway, this seems quite cool.
Class diagram: (I am not an expert @ UML)
Existing solutions:
- for PHP
- for Python
Tuesday, May 18, 2010
Monday, May 10, 2010
BLOBing in Mongo
import pymongo
import urllib2
import wx
import sys
from pymongo import Connection
class Image:
def __init__(self):
self.connection = pymongo.Connection()
self.database = self.connection.newStore
self.collection = self.database.newColl
self.imageName = "Uninitialized"
self.imageData = ""
def loadImage(self, imageUrl, imageTitle = "Undefined"):
try:
ptrImg = urllib2.Request(imageUrl)
ptrImgReq = urllib2.urlopen(ptrImg)
imageFeed = ptrImgReq.read()
self.imageData = pymongo.binary.Binary(imageFeed, pymongo.binary.BINARY_SUBTYPE)
self.imageName = imageTitle
ptrImgReq.close()
except:
self.imageName = "Error " + str(sys.exc_info())
self.imageData = None
def persistImage(self):
if self.imageData == None:
print 'No data to persist'
else:
print 'Persisting ' + self.imageName
self.collection.insert({"name":self.imageName, "data":self.imageData})
self.imageData = None
def renderImage(self, parm = None):
if parm == None:
self.imageData = self.collection.find_one({"name":self.imageName})
else:
self.imageName = parm
self.imageData = self.collection.find_one({"name":self.imageName})
ptrApp = wx.PySimpleApp()
fout = file('d:/tmp.jpg', 'wb')
fout.write(self.imageData["data"])
fout.flush()
fout.close()
wximg = wx.Image('d:/tmp.jpg',wx.BITMAP_TYPE_JPEG)
wxbmp = wximg.ConvertToBitmap()
ptrFrame = wx.Frame(None, -1, "Show JPEG demo")
ptrFrame.SetSize(wxbmp.GetSize())
wx.StaticBitmap(ptrFrame, -1, wxbmp, (0,0))
ptrFrame.Show(True)
ptrApp.MainLoop()
img = Image()
img.loadImage('http://i208.photobucket.com/albums/bb82/julianzzkj/Acapulco/e614.jpg', 'Acapulco at night')
img.persistImage()
img.renderImage('Acapulco at night')
I have had some problems with installing PIL, so this is certainly not optimal (I have to use wx for image rendering instead, and I have not found a way of feeding a JPG datastream to an image constructor, hence the ugly recourse to a temporary file). However, the idea was to test how the database can store an image, which seems to work quite well, despite taking a few seconds to load a 300kb file.
A findOne query returns:
> db.newColl.findOne()
{
"_id" : ObjectId("4be82f74c7ccc11908000000"),
"data" : BinData type: 2 len: 345971,
"name" : "Acapulco at night"
}
>
Thanks are due for some of the wx code.
Thursday, April 29, 2010
Some thoughts on NoSQL
- Mongo is cool. I definitely like it. However, it differs from Cache in one important way: JSON objects are native to JavaScript. To everything else, they are just a text format (that Python can understand easily, true) not necessarily any more efficient than XML. Cache objects are more or less portable across languages and the impedance mismatch between the consumer and the database is definitely much less significant than in the case of Mongo;
- Mongo is fast, and easy enough to understand for perhaps a dozen or two 'collections'. I am not sure how well it would support (or perform) with a 3000-table schema, which is not at all unlikely in an enterprise application. While the proliferation of tables is a perverse effect of relational normalization, the fact is that the relational model is easy to understand. Complex text representations of object hierarchies, which Mogo really allows for, might quickly spin out of control (assuming that the schema is kept under control by restricting access to the database through the front end, and object collections to not degenerate to the point of being simple bit buckets);
- so Mongo might be best appropriate in an environment with a few deep entities with loose connections: e.g. 12-25 'tables' with million+ rows, especially for client apps that can read JSON (or derivatives: such as Python's collection objects) more or less natively.
- VoltDB @ InformationWeek
- and @ RWW
Twitter Python Mongo
import urllib
import json
import string
from pymongo import Connection
def runQuery(query, pp, pages):
ret = []
for pg in range(1, pages+1):
print 'page...' + str(pg)
p = urllib.urlopen('http://search.twitter.com/search.json?q=' + query + '&rpp=' + str(pp) + '&page=' + str(pg))
s = json.load(p)
dic = json.dumps(s)
dic = string.replace(dic, 'null', '"none"')
dx = eval(dic)
listOfResults = dx['results']
for result in listOfResults:
ret.append( { 'id':result['id'], 'from_user':result['from_user'], 'created_at':result['created_at'], 'text': result['text'] } )
completeRet = {"results": ret}
return completeRet
c = Connection()
d = c.twitterdb
coll = d.postbucket
res = runQuery('Iran', 100, 15)
ptrData = res.get('results')
for item in ptrData:
coll.save(item)
A Twitter Python web service
import urllib
import json
import string
import SimpleXMLRPCServer
from SimpleXMLRPCServer import SimpleXMLRPCServer
from SimpleXMLRPCServer import SimpleXMLRPCRequestHandler
def runQuery(query, pp, pages):
p = urllib.urlopen('http://search.twitter.com/search.json?q=' + query + '&rpp=' + str(pp) + '&page=' + str(pages))
s = json.load(p)
dic = json.dumps(s)
dic = string.replace(dic, 'null', '"none"')
dx = eval(dic)
listOfResults = dx['results']
ret = []
for result in listOfResults:
ret.append( { 'id':result['id'], 'from_user':result['from_user'], 'created_at':result['created_at'], 'text': result['text'] } )
completeRet = {"results": json.dumps(str(ret))}
return str(completeRet)
class RequestHandler(SimpleXMLRPCRequestHandler):
rpc_paths=('/RPC2')
server=SimpleXMLRPCServer(("localhost", 8000), requestHandler=RequestHandler)
server.register_introspection_functions()
server.register_function(runQuery, 'qry')
server.serve_forever()
More potential uses of this (including Google Apps, Mongo, or Processing) later. And here is how to use it (from Python):
>>> import xmlrpclib
>>> s = xmlrpclib.ServerProxy('http://localhost:8000')
>>> print s.qry('Bumrungrad', 10, 1)
Where the first numeric parameter is the number of records per page and the second, the number of page (max 100/15).




