Since I have joined InterSystems a while ago, I thought a Caché post might be appropriate, especially since it illustrates quite nicely the various data access modes offered by the platform.
Below is a routine called TestModes.mac, invoked by a >do ^TestModes. The SQLCompile macro is necessary because the SQL code references objects which do not exist compile time, before CreateTable is run (InsertData). The multi-dimensional sparse arrays created as SQL tables (by CreateTable) are accessed in multi-value mode by ReadMV and deleted by DropMV (which also uses the DeleteExtent method of the data objects to perform a ‘table truncation’ on the data objects).
Another nice feature is the extraction of the list items from the arrays (table data rows are stored as array items, whereby each field is stored in a string list created by $LISTBUILD) back to strings by the $LISTTOSTRING function.
Some legacy features are visible (the need to declare SQLCODE as a public variable and make it NEW to restrict it to the current scope). I don’t think that this kind of mix would make sense in an application, where it would make sense to use one access metaphor and only one for a given data item; but this is still a valuable example which ties the data architecture(s) of Caché together nicely.
TestModes
; shows the different data access types
; SQL, MV, class
#SQLCompile Mode = DEFERRED
DO CreateTable
DO InsertData(1000)
DO ReadMV
DO DropMV
WRITE $$ReadData()
QUIT
;
CreateTable()
{
&sql( DROP TABLE items)
&sql( CREATE TABLE items(id INT, data VARCHAR(50)))
QUIT
}
InsertData(upto)[SQLCODE]
{
#DIM x as %String
#DIM i as %Integer
NEW SQLCODE
FOR i = 1:1:upto
{
SET x = i _ " DataItem"
&sql( INSERT INTO SQLUser.items(id, data) VALUES( :i, :x))
IF (SQLCODE '= 0 )
{
WRITE "SQL error:", $ZERROR, !
}
}
QUIT
}
ReadMV()
{
#DIM ky AS %String
#DIM extr AS %String
WRITE "Navigating the data", !
SET ky = $ORDER(^User.itemsD(""))
WHILE( ky '= "")
{
; WRITE ky, ^User.itemsD(ky), !
SET ky = $ORDER(^User.itemsD(ky))
IF ( ky '= "" )
{
SET extr = $LISTTOSTRING(^User.itemsD(ky))
WRITE ?5, extr, !
}
}
QUIT
}
DropMV()
{
DO ##class(User.items).%DeleteExtent()
KILL ^User.itemsD
QUIT
}
ReadData() [SQLCODE]
{
#Dim result AS %String
NEW SQLCODE
&sql(SELECT COUNT(*) INTO :result FROM SQLUser.items )
; the table is still there, but empty
IF (SQLCODE '= 0) SET result = "Error " _ $ZERROR
Q result
}
Sunday, September 26, 2010
Tuesday, June 29, 2010
MySQL and SQL Server
...actually, how to make the two talk.
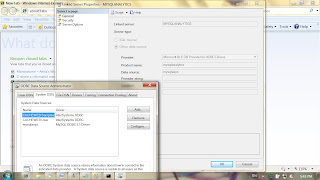
To query (from SQL Server):
Create a Linked Server in SQL Server (using ODBC):
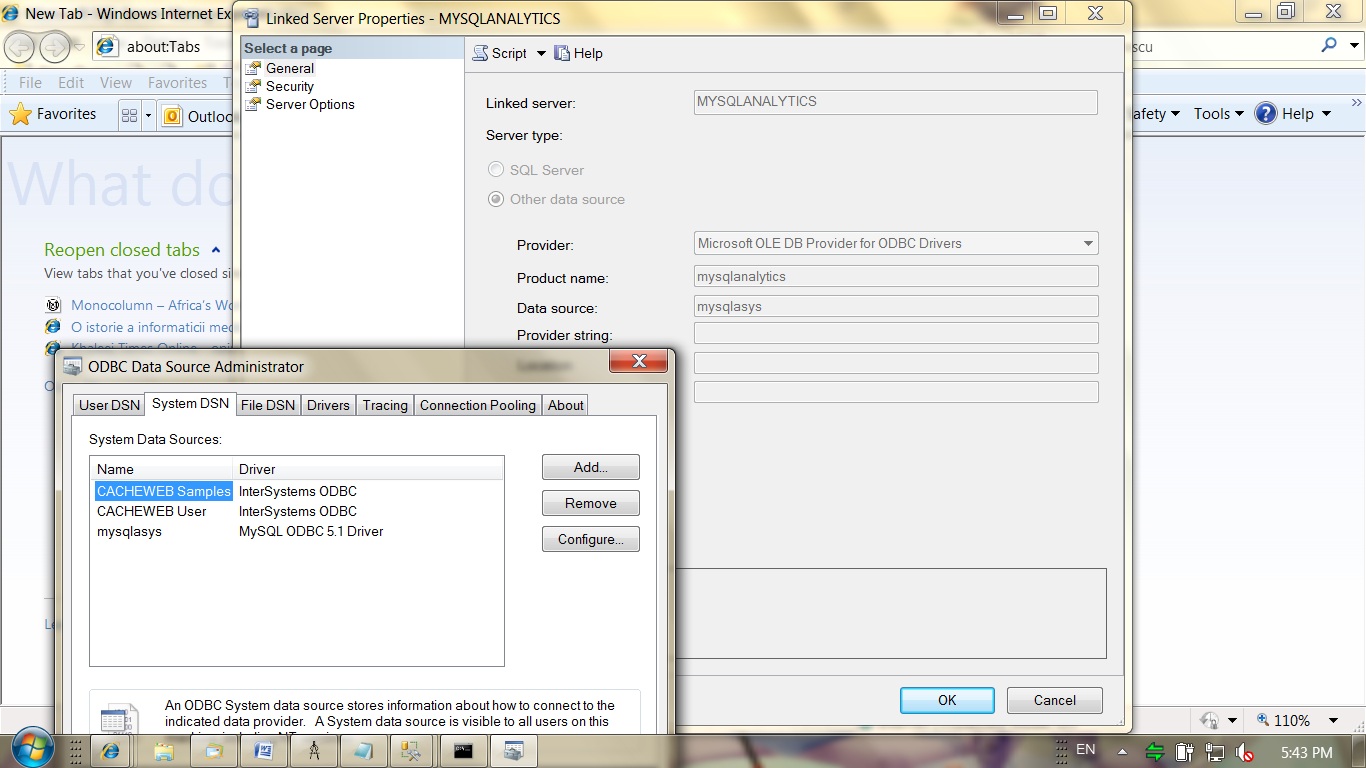
To query (from SQL Server):
select top 5 * from mysqlanalytics...analytics;
select * from mysqlanalytics...session;
Stored procedures aren't available, but you can get around this by writing a view in MySQL to return the data from the stored procedure (and perhaps use a table to get any parameters the stored procedure might need).
mysql> create view ViewSession as
-> select GetSession() as CurrentSession;
Query OK, 0 rows affected (0.06 sec)
mysql> select * from viewsession;
+----------------+
CurrentSession
+----------------+
1
+----------------+
And ViewSession is now available in SQL Server:
select * from mysqlanalytics...ViewSession
Friday, June 25, 2010
Wednesday, June 16, 2010
Monday, June 14, 2010
Wednesday, June 09, 2010
CMS everywhere
This is old news, but it is interesting to see how ASP.MVC follows the same principles as, for example, Django or Zope; it contains the building blocks for a CMS, and supersedes the ASP.NET paradigm.
That being said, there are conceptual differences - Zope is middleware-centric (the database is customized for it), Django is database-centric (you start with the db definition, even if it is done at the ORM level: you start with the classes in Python which then get mapped to relational tables) and ASP.MVC is purely database centric (using LINQ to SQL - the classes are generated from the relational tables).
Finally you have something like eZ Publish where objects exist somewhere between PHP and the CMS, and are stored in a bit bucket (relational database, but with no relational features per se, so they might be better off using Mongo or Cache for speed).
Other than that, same features - URL mapping, templates, etc.
Next, I'll delve into ZODB, it would be interesting to see how much is actually stored there and how much in /var.
That being said, there are conceptual differences - Zope is middleware-centric (the database is customized for it), Django is database-centric (you start with the db definition, even if it is done at the ORM level: you start with the classes in Python which then get mapped to relational tables) and ASP.MVC is purely database centric (using LINQ to SQL - the classes are generated from the relational tables).
Finally you have something like eZ Publish where objects exist somewhere between PHP and the CMS, and are stored in a bit bucket (relational database, but with no relational features per se, so they might be better off using Mongo or Cache for speed).
Other than that, same features - URL mapping, templates, etc.
Next, I'll delve into ZODB, it would be interesting to see how much is actually stored there and how much in /var.
Speaking of ASP.MVC, here are a couple of links on SEO, relevant to other CMS as well (especially to migrations!):
Tuesday, June 08, 2010
Python classes
Old-style:
class OldClass:
def method(self):
….
Characterized by:
P = OlcClass()
p.__class__ à 'OldClass'
type(p) à 'instance'
>>> class Test:
def __init__(self):
print 'Test initialized'
def meth(self):
self.member = 1
print 'Test.member = ' + str(self.member)
>>> class TestKid(Test):
"This is derived from Kid, meth is overriden and so is member"
def __init__(self):
print 'Kid initialized'
def meth(self):
self.member = 2
Test.meth(self)
print 'Kid.member = ' + str(self.member)
Above is shown how to override a method, call its parent implementation; the member attribute is shared between the parent and child classes and hence calling a function in parent which references it will modify it in the child as well. The parent constructor (or any other overridden function) is not called by default.
New-style:
>>> class Test(object):
Type(p) would return 'Test'. Unifies types and classes.
It has classmethods and staticmethods.
Also (for both old and new):
P = Test() ; calling a class object yields a class instance
p.__dict__ à {'member':1}
p.__dict__['member'] = 1 ; same as p.member
You can use properties (almost .NET-style) to access class attributes with new classes.
More.
Thursday, May 27, 2010
Images in SQL Server
A simple .NET class to dump image data into/from SQL Server. I'd like to explore a potential alternative to this using FILESTREAM.
In T-SQL:
In Python/MySQL, this is done like this: (the image column, image_data, is defined as BLOB in MySQL)
blob is a string type.
In T-SQL:
update version set [file] = BulkColumn from
openrowset(bulk 'e:\....jpg', single_blob) as [file]
where ...;
In Python/MySQL, this is done like this: (the image column, image_data, is defined as BLOB in MySQL)
>>> import MySQLdb
>>> connection = MySQLdb.connect('','root','','RTest')
>>> blob = open('d:\\pic1.jpg', 'rb').read()
>>> sql = 'INSERT INTO rtest.mm_image(image_data, mm_person_id_mm_person) VALUES(%s, 1)'
>>> args = (blob,)
>>> cursor = connection.cursor()
>>> cursor.execute(sql, args)
>>> connection.commit()
blob is a string type.
Wednesday, May 26, 2010
CMSRDBMSWT..?
There seems to be precious little information on data management in the context of CMS (Content Management Systems). To me, this would seem very important - data admin, modeling, etc, all should be hugely important, and yet some of the CMS I come across are little more than bit buckets with a data dictionary. While web-based CMS have certainly driven the development of NoSQL (due to performance reasons, given the underoptimal use of the RDBMS by the CMS), certainly some thought has gone into the data layer of the CMS... where is it at?
Speaking of CMS: Here's Plone, which is running on a NoSQL incidentally.
Speaking of CMS: Here's Plone, which is running on a NoSQL incidentally.
Thursday, May 20, 2010
Python ORM
A first shot at ORMing in Python.
The second, improved shot. Inheritance/polymorphism in weakly-typed languages such as Python is a bit hard to grasp at first. Anyway, this seems quite cool.
Class diagram: (I am not an expert @ UML)
Existing solutions:
- for PHP
- for Python
The second, improved shot. Inheritance/polymorphism in weakly-typed languages such as Python is a bit hard to grasp at first. Anyway, this seems quite cool.
Class diagram: (I am not an expert @ UML)
Existing solutions:
- for PHP
- for Python
Tuesday, May 18, 2010
Monday, May 10, 2010
BLOBing in Mongo
SQL Server, Oracle, Cache, etc, all have binary streams, and offer various ways of storing binary data (such as images) directly into the database. I was curious to see how this would work with Mongo, and here is the result:
I have had some problems with installing PIL, so this is certainly not optimal (I have to use wx for image rendering instead, and I have not found a way of feeding a JPG datastream to an image constructor, hence the ugly recourse to a temporary file). However, the idea was to test how the database can store an image, which seems to work quite well, despite taking a few seconds to load a 300kb file.
A findOne query returns:
Thanks are due for some of the wx code.
import pymongo
import urllib2
import wx
import sys
from pymongo import Connection
class Image:
def __init__(self):
self.connection = pymongo.Connection()
self.database = self.connection.newStore
self.collection = self.database.newColl
self.imageName = "Uninitialized"
self.imageData = ""
def loadImage(self, imageUrl, imageTitle = "Undefined"):
try:
ptrImg = urllib2.Request(imageUrl)
ptrImgReq = urllib2.urlopen(ptrImg)
imageFeed = ptrImgReq.read()
self.imageData = pymongo.binary.Binary(imageFeed, pymongo.binary.BINARY_SUBTYPE)
self.imageName = imageTitle
ptrImgReq.close()
except:
self.imageName = "Error " + str(sys.exc_info())
self.imageData = None
def persistImage(self):
if self.imageData == None:
print 'No data to persist'
else:
print 'Persisting ' + self.imageName
self.collection.insert({"name":self.imageName, "data":self.imageData})
self.imageData = None
def renderImage(self, parm = None):
if parm == None:
self.imageData = self.collection.find_one({"name":self.imageName})
else:
self.imageName = parm
self.imageData = self.collection.find_one({"name":self.imageName})
ptrApp = wx.PySimpleApp()
fout = file('d:/tmp.jpg', 'wb')
fout.write(self.imageData["data"])
fout.flush()
fout.close()
wximg = wx.Image('d:/tmp.jpg',wx.BITMAP_TYPE_JPEG)
wxbmp = wximg.ConvertToBitmap()
ptrFrame = wx.Frame(None, -1, "Show JPEG demo")
ptrFrame.SetSize(wxbmp.GetSize())
wx.StaticBitmap(ptrFrame, -1, wxbmp, (0,0))
ptrFrame.Show(True)
ptrApp.MainLoop()
img = Image()
img.loadImage('http://i208.photobucket.com/albums/bb82/julianzzkj/Acapulco/e614.jpg', 'Acapulco at night')
img.persistImage()
img.renderImage('Acapulco at night')
I have had some problems with installing PIL, so this is certainly not optimal (I have to use wx for image rendering instead, and I have not found a way of feeding a JPG datastream to an image constructor, hence the ugly recourse to a temporary file). However, the idea was to test how the database can store an image, which seems to work quite well, despite taking a few seconds to load a 300kb file.
A findOne query returns:
> db.newColl.findOne()
{
"_id" : ObjectId("4be82f74c7ccc11908000000"),
"data" : BinData type: 2 len: 345971,
"name" : "Acapulco at night"
}
>
Thanks are due for some of the wx code.
Thursday, April 29, 2010
Some thoughts on NoSQL
So I have been playing with various database systems, many pertaining to the NoSQL category. Here are some thoughts:
More on this:
- Mongo is cool. I definitely like it. However, it differs from Cache in one important way: JSON objects are native to JavaScript. To everything else, they are just a text format (that Python can understand easily, true) not necessarily any more efficient than XML. Cache objects are more or less portable across languages and the impedance mismatch between the consumer and the database is definitely much less significant than in the case of Mongo;
- Mongo is fast, and easy enough to understand for perhaps a dozen or two 'collections'. I am not sure how well it would support (or perform) with a 3000-table schema, which is not at all unlikely in an enterprise application. While the proliferation of tables is a perverse effect of relational normalization, the fact is that the relational model is easy to understand. Complex text representations of object hierarchies, which Mogo really allows for, might quickly spin out of control (assuming that the schema is kept under control by restricting access to the database through the front end, and object collections to not degenerate to the point of being simple bit buckets);
- so Mongo might be best appropriate in an environment with a few deep entities with loose connections: e.g. 12-25 'tables' with million+ rows, especially for client apps that can read JSON (or derivatives: such as Python's collection objects) more or less natively.
- VoltDB @ InformationWeek
- and @ RWW
Twitter Python Mongo
...or how many buzzwords can you get in one title. Here is a shortish piece of code that pulls data from Twitter and inserts it into Mongo. Other than the shortness of the code (given what it accomplishes!), what is remarkable is the ease of use of the data that is passed around, with a minimum amount of marshalling: Twitter can return data in JSON which is the native Mongo format and Python can use with a minimum of tweaking (mostly to reduce the response from Twitter).
import urllib
import json
import string
from pymongo import Connection
def runQuery(query, pp, pages):
ret = []
for pg in range(1, pages+1):
print 'page...' + str(pg)
p = urllib.urlopen('http://search.twitter.com/search.json?q=' + query + '&rpp=' + str(pp) + '&page=' + str(pg))
s = json.load(p)
dic = json.dumps(s)
dic = string.replace(dic, 'null', '"none"')
dx = eval(dic)
listOfResults = dx['results']
for result in listOfResults:
ret.append( { 'id':result['id'], 'from_user':result['from_user'], 'created_at':result['created_at'], 'text': result['text'] } )
completeRet = {"results": ret}
return completeRet
c = Connection()
d = c.twitterdb
coll = d.postbucket
res = runQuery('Iran', 100, 15)
ptrData = res.get('results')
for item in ptrData:
coll.save(item)
A Twitter Python web service
Taking the code from the previous post: here is a Python web service that reads the Twitter feed for a given query and returns a subset of the results in JSON:
More potential uses of this (including Google Apps, Mongo, or Processing) later. And here is how to use it (from Python):
Where the first numeric parameter is the number of records per page and the second, the number of page (max 100/15).
import urllib
import json
import string
import SimpleXMLRPCServer
from SimpleXMLRPCServer import SimpleXMLRPCServer
from SimpleXMLRPCServer import SimpleXMLRPCRequestHandler
def runQuery(query, pp, pages):
p = urllib.urlopen('http://search.twitter.com/search.json?q=' + query + '&rpp=' + str(pp) + '&page=' + str(pages))
s = json.load(p)
dic = json.dumps(s)
dic = string.replace(dic, 'null', '"none"')
dx = eval(dic)
listOfResults = dx['results']
ret = []
for result in listOfResults:
ret.append( { 'id':result['id'], 'from_user':result['from_user'], 'created_at':result['created_at'], 'text': result['text'] } )
completeRet = {"results": json.dumps(str(ret))}
return str(completeRet)
class RequestHandler(SimpleXMLRPCRequestHandler):
rpc_paths=('/RPC2')
server=SimpleXMLRPCServer(("localhost", 8000), requestHandler=RequestHandler)
server.register_introspection_functions()
server.register_function(runQuery, 'qry')
server.serve_forever()
More potential uses of this (including Google Apps, Mongo, or Processing) later. And here is how to use it (from Python):
>>> import xmlrpclib
>>> s = xmlrpclib.ServerProxy('http://localhost:8000')
>>> print s.qry('Bumrungrad', 10, 1)
Where the first numeric parameter is the number of records per page and the second, the number of page (max 100/15).
Wednesday, April 28, 2010
Twitter API
A bit of topical coding.... getting tweets regarding the situation in Bangkok:
It's the first time I try the Twitter API, and it seems simple enough!
>>> import urllib
>>> from xml.dom import minidom
>>> p=urllib.urlopen('http://search.twitter.com/search.atom?q=Bangkok')
>>> xml=minidom.parse(p)
>>> p.close()
>>> nodes=xml.getElementsByTagName('title')
>>> for node in nodes:
print node.firstChild.NodeValue
It's the first time I try the Twitter API, and it seems simple enough!
Tuesday, April 27, 2010
Mongo and Cache
Some similarities:
For now I have a couple of other questions:
Also, if you store objects with different structures in one collection, they can be inspected:
Lots of interesting info at the Wikipedia JSON page.
- the system-generated row id: (_id for Mongo)
- object references, and a kind of relationship definition in Mongo:
> x = {name:'Lab test'}
{ "name" : "Lab test" }
> db.second.save(x)
> pat = {name:'Amornrakot', test:[new DBRef('second', x._id)]}
{
"name" : "Amornrakot",
"test" : [
{
"$ref" : "second",
"$id" : ObjectId("4bd6d7c64e660000000f665a")
}
]
}
> pat.test[0].fetch()
{ "_id" : ObjectId("4bd6d7c64e660000000f665a"), "name" : "Lab test" }
The similarities aren't surprising perhaps; it is the differences that trouble me (in this case, Mongo's looseness - lack of structure); although SQLite was the first one to go down that path, by not enforcing strict data typing, and now Mongo doesn't even enforce schemas. A discussion on Mongo database design principles here.
For now I have a couple of other questions:
- is there a reporting tool that binds to JSON/Mongo natively?
- how do you update an existing JSON entry? just one tuple, not the entire record; some notes:
- var p = db.coll.findOne();
- p.member (notation supported, p is an object already and there is no need to eval() it; originally, say p{member:"y"} ) = "x" and now p is disconnected from the collection, but db.coll.save(p) does update it in place
What is cool is that you can save JS objects (declared using the JS object notation):
function pobj(param){this.p1=param;}
var newObj = new pobj("test");
db.coll.save(newObj);
db.coll.find(); returns { "_id" : ObjectId("4bd722a6eb29000000007ac4"), "p1" : "test" }. You can even 'serialize' objects' methods, and then call the method for the objects deserialized using findOne. All of this might be JS-specific candy, I am curious how this ports over to other language drivers.
So you can view Mongo as a (JS) object-oriented database, with nothing in the way of SQL facilities though; a tuple serialization mechanism; a key-value pair list; a 'document'/hierarchical database using JSON as the document format (as opposed to xDB's XML), all of which are correct.
Another question: when you have an embedded object, var ptrUser = {name : "Mr Iwata", address : { city : "Tokyo }}, how do you search by the inner object properties? db.coll.find({address:{ city : "criteria" }} does not seem to work.RTfM
Also, if you store objects with different structures in one collection, they can be inspected:
from pymongo import Connection
c = Connection()
d = c.clinical
coll = d.physician
for item in coll.find():
itmkeys = []
print item.get("_id")
for ky in item.iterkeys():
itmkeys.append(ky)
print itmkeys
Lots of interesting info at the Wikipedia JSON page.
Monday, April 26, 2010
Very basic Google Chart
- create the URL
- you can then pull it in Python:
>>> import urllib
>>> p=urlopen('http://chart.apis.google.com/chart?chs=250x100&chd=t:60,40,90,20&cht=p3')
>>> data = p.read()
>>> f = file('d:\\file.png', 'wb')
>>> f.write(data)
>>> f.close()
It's quite easy to build the URL based on the data in a Googledoc spreadsheet: (code modified from Google's own documentation)
try:
from xml.etree import ElementTree
except ImportError:
from elementtree import ElementTree
import gdata.spreadsheet.service
import gdata.service
import atom.service
import gdata.spreadsheet
import atom
import string
def main():
gd_client = gdata.spreadsheet.service.SpreadsheetsService()
gd_client.email = '______________@gmail.com'
gd_client.password = '________'
gd_client.source = 'SpreadSheet data source'
gd_client.ProgrammaticLogin()
print 'List of spreadsheets'
feed = gd_client.GetSpreadsheetsFeed()
PrintFeed(feed)
key = feed.entry[string.atoi('0')].id.text.rsplit('/', 1)[1]
print 'Worksheets for spreadsheet 0'
feed = gd_client.GetWorksheetsFeed(key)
PrintFeed(feed)
key_w = feed.entry[string.atoi('0')].id.text.rsplit('/', 1)[1]
print 'Contents of worksheet'
feed = gd_client.GetListFeed(key, key_w)
PrintFeed(feed)
return
def PrintFeed(feed):
for i, entry in enumerate(feed.entry):
if isinstance(feed, gdata.spreadsheet.SpreadsheetsCellsFeed):
print 'Cells Feed: %s %s\n' % (entry.title.text, entry.content.text)
elif isinstance(feed, gdata.spreadsheet.SpreadsheetsListFeed):
print 'List Feed: %s %s %s' % (i, entry.title.text, entry.content.text)
print ' Contents:'
for key in entry.custom:
print ' %s: %s' % (key, entry.custom[key].text)
print '\n',
else:
print 'Other Feed: %s. %s\n' % (i, entry.title.text)
if __name__ == "__main__":
main()
Friday, April 23, 2010
NHS Choices on GoogleApps

Here is the Google Apps version of the (Python) NHS Choices application I discussed in the previous posts.
I can't even begin to say how cool this is. 3 hours in Notepad (hence the crudeness) and we get the hospitals in the UK, from anywhere. This is really amazing.
The source code.
Sunday, April 11, 2010
Searching in Python
There is perhaps a more Pyhton-specific way of storing the data to be loaded into the Mongo database: a list of dictionaries. In this case, a dictionary is defined as {'name':__name__, 'service':__service__, 'web':__web__}.To add an element to the holding list (say, NHS): NHS.append({'name':'Wigan General', 'service':5, 'web':None}). Then, a function can be defined which will return the index of the list containing the element matching its parameter; i.e.:
>>> def idx(ky, val):
for item in NHS:
if item[ky] == val:
return NHS.index(item)
Usage:
>>> print idx('name', 'Wigan General')
will yield Wigan's index in the list. I'm quite curious how fast this is with several thousand records! But Python's ability to easily make sense of a complex data structure is impressive.
Another way of searching, using list comprehensions:
>>> def idx2(ky, val):
lstIdx = [item[ky] == val for item in NHS]
return lstIdx.index(True)
It would also be interesting to know if the bytecode generated by Python is different between the two.
Saturday, April 10, 2010
Mongo, Python, and NHS Choices
Using Python, NHS open data (NHS Choices), and Mongo: for example, getting the name and the web sites of all the providers in the Wigan area (why Wigan? No idea, just that their football team seems to be pretty bad recently defeated Arsenal, and the name stuck with me).
Start the database: go to the bin subdirectory of the install directory, and type mongod –dbpath .\
I will connect to the database using the Python API (pymongo).
NHS choices offers several health data feeds:
- News
- Find Services
- Live Well
- Health A-Z (Conditions)
- Common Health Questions
As mentioned, I will use the second; to access it, you need to get a password and a login (apply for one here).
The basic Python code to query for providers and extract their names and web addresses is this:
First, build a list of services, as per the NHS documentation (the service code and the location are two required parameters):
services = [[1, 'GPs'], [2,'Dentists'], etc]
Then, query the web service:
for x in range(0, len(services)):
endpoint='http://www.nhs.uk/NHSCWS/Services/ServicesSearch.aspx?user=__login__&pwd=__password__&q=Wigan&type=' + str(x)
usock=urllib.urlopen(endpoint)
xmldoc=minidom.parse(usock)
usock.close()
nodes = xmldoc.getElementsByTagName("Service")
for node in nodes:
website = node.getElementsByTagName("Website")
name = node.getElementsByTagName("Name")
if website[0].firstChild <> None:
xmldoc.unlink()
The response will have a 3-item dataset, the service type, the provider name, and the web site (if one exists).
Mongo is a bit different in that the 'server' does not create a database physically until something is written to that database, so from the console client (launch, in \bin\: mongo) you can connect to a database that does not exist yet (use NHS in this case will create the NHS database - in effect, it will create files named NHS in the current directory).
Creating the 'table' from the console client: NHS = { service : "service", name : "name", website : "website" };
db.data.save(NHS); will create a collection (similar to SQL namespaces) and save the NHS table into it. The mongo client uses JavaScript as language and JSON notation to define the tables.
To access this collection in Python:
>>> from pymongo import Connection
>>> connection = Connection()
>>> db=connection.NHS
>>> storage=db.data
>>> post={"service" : 1, "name" : "python", "website" : "mongo" }
>>> storage.insert(post)
Here is the full code in Python to populate the database:
import urllib
from xml.dom import minidom
from pymongo import Connection
print "Building list of services..."
services = [[1, 'GPs'], [2,'Dentists'], [3, 'Pharmacists'], [4, 'Opticians'], [5, 'Hospitals'], [7, 'Walk-in centres'],[9, 'Stop-smoking services'], [10, 'NHS trusts'], [11, 'Sexual health services'], [12,' DISABLED (Maternity units)'], [13, 'Sport and fitness services'], [15, 'Parenting & Childcare services'], [17, 'Alcohol services'], [19, 'Services for carers'], [20, 'Renal Services'], [21, 'Minor injuries units'], [22, 'Mental health services'], [23, 'Breast cancer screening'], [24, 'Support for independent living'], [26, 'Memory problems'], [27, 'Termination of pregnancy (abortion) clinics'], [28, 'Foot services'], [29, 'Diabetes clinics'], [30, 'Asthma clinics'], [31,' Midwifery teams'], [32, 'Community clinics']]
print "Connecting to the database..."
connection = Connection()
db = connection.NHS
storage = db.data
print "Scanning the web service..."
for x in range(0, len(services)):
print '*** ' + services[x][1] + ' ***'
endpoint='http://www.nhs.uk/NHSCWS/Services/ServicesSearch.aspx?user=__login__&pwd=__password__&q=Wigan&type=' + str(x)
usock=urllib.urlopen(endpoint)
xmldoc=minidom.parse(usock)
usock.close()
nodes = xmldoc.getElementsByTagName("Service")
for node in nodes:
website = node.getElementsByTagName("Website")
name = node.getElementsByTagName("Name")
namei = name[0].firstChild.nodeValue
if website[0].firstChild <> None:
websitei = ' ' + website[0].firstChild.nodeValue
else:
websitei = 'none'
post = { "service" : x, "name" : namei, "website" : websitei }
storage.insert(post)
xmldoc.unlink()
To see the results from the Mongo client:
> db.data.find({service:5}).forEach(function(x){print(tojson(x));});
Will return all the hospitals inserted in the database (service for hospitals = 5); the response looks like this:
{
"_id" : ObjectId("4bc062dbc7ccc10428000032"),
"website" : " http://www.wiganleigh.nhs.uk/Internet/Home/Hospitals/tlc.asp",
"name" : "Thomas Linacre Outpatient Centre",
"service" : 5
}
Next, it might be interesting to try this using Mongo's REST API, and perhaps to build a GoogleApp to do so.
Friday, April 09, 2010
Internet, 247

This is tiresome. I've complained about it before. Until there is a seamless Internet experience, where things work most of the time, I won't buy into the Internet platform. It's unreliable.
Mongo

Yet another non-relational database. There definitely seems to be a trend in that direction, a market corner that the RDBMS's do not address convincingly. I would guess that for a general purpose system, which might have power users/report writers, a full-fledged database makes sense, but for a turnkey system where speed is important and there is no need to expose too much of the internals to the users, this type of offering is useful.
Saturday, April 03, 2010
More Cache-specific features
Using dates in Cache: (an alternative to this)
- Class Person…. { DOB As %Date }
- INSERT INTO Person(… DOB) VALUES(…, TO_DATE('12 Jan 1989')
Using queries in Cache:
Class HIS.Patient Extends %Persistent
{
Property Name As %String;
Property DOB As %Date;
Property Inpatient As %Boolean;
/// Class query
Query GetInpatients(Inpatient As %Boolean=1) As %SQLQuery(SELECTMODE="RUNTIME")
{
SELECT * FROM Patient
WHERE Inpatient = :Inpatient
ORDER BY Name
}
}
Insert some data in SQL, then:
- S rset=##class(%RecordSet).%New()
- S rset.ClassName="HIS.Patient"
- S rset.QueryName="GetInpatients"
- Do rset.Execute(1)
- W rset.Next()
- If result is 1, w rset.Data("Name")
Cache Streams
Used to store large (>32k) amounts of data:
- binary
- character
Hence, streams are supersized binary (%Binary) or character (%String) types. The difference with other databases systems is that streams in Cache can be stored in external files or database global variables.
The following code:
Class CM.Patient Extends %Persistent
{
Property PatientName As %String;
Property PatientData As %FileCharacterStream(LOCATION = "D:/");
}
Executed in Terminal:
> DO %^CD
> S p = ##class(CM.Patient).%New()
> DO p.PatientData.Write("Test")
Will create a temporary file on drive D: where the "Test" string will be written to; when the Terminal session ends, the file will be deleted as the object is garbage-collected. In the order for the stream to persist, you have to %Save() the object.
SQL Server just recently started offering FILESTREAMs.
Wednesday, March 31, 2010
Everything is searchable
Interesting things happening while I wasn't watching. Not only the previously mentioned Data.gov, or the newspapers moving in the same direction, but also ...
I'm really curious what effect will this have on databases. In theory, with the right authentication in place, everything could be exposed online and EDI would be vastly simplified, from sneakernet to HL7, everything would be replaced by REST calls.
At any rate, Freebase's attempt to organize everything is ambitious/stunning.
Wikipedia's own API, here.
Related: Talis.
Data.gov
US Government's open data initiative. Interesting, have to find out more about what's there. The potential for mashups and visualizations is great... if the data is trusted and current.
Here is the equivalent UK site.
I need to look into this some more, for now a lot of the data seems to be Excel files that can be downloaded. No universal REST/JSON access?
Here is the equivalent UK site.
I need to look into this some more, for now a lot of the data seems to be Excel files that can be downloaded. No universal REST/JSON access?
Saturday, March 27, 2010
Sunday, March 21, 2010
Interface engines
Unbeknownst to myself, in a previous job I wrote an interface engine. It was a (initially) simple VB application which was reading files from a directory and copying them to another directory, then deleting them from the source. Then more source directories were added. Then, file endings had to determine the destination. Then, file contents (i.e., header or template-based triggers) had to determine which files were copied and which not. Finally, database tables became source/destinations. The thing had grown immensely since the beginning and it was running 24/7, with a 30 second polling interval, and a large number of customers were relying in fact on a rickety PC running a hopelessly spaghetti-coded application with manually-installed DLLs. If only they knew.
I did not know at the time that this was an interface engine. Somewhat restricted to healthcare and financial IT, one wonders why this concept hasn't taken off in mainstream computing more significantly. I.e., in databases, interfaces could provide a strong and pervasive (cross-platform, even) replication/synchronization mechanism.
Or perhaps the concept has been folded into workflow engines and transaction-based orchestration systems; Biztalk or Oracle Fusion can presumably do what interface engines do, and much more – but at a hefty footprint.
Mirthcorp's Java-based interface engine, below, running against a Cache database over JDBC/ODBC.
Message passing:

Channel definition:

A web-based interface engine? Perhaps using technology similar to YQL. Monitoring a queue of some kind and updating your Facebook status? Have to think about this one.
Saturday, March 20, 2010
Cache dates
Cache's multiple interfaces (RDMBS, OO) can cause confusion even for simple operations, such as inserting dates. Here is how that is done:
In SQL:
insert into CM.StrmClass(PatientAddress, PatientName, PatientDateOfBirth)
values('5 Soi Rangnam Bangkok, Thailand', 'TG', {d '1990-03-17'})
Rather ugly ODBC formatting for the date field. In Object Script:
Set p.PatientDateOfBirth = $ZDateh("12/21/1977")
By the way, if a %Save fails (does not make the results commit to the database), then there is a problem with the data validation. Running the container from the Terminal should show the result (e.g. W p.%Save())
Another interesting feature of Cache, which accounts for its performance: 'Using a unique feature known as “subscript mapping,” you can specify how the data within one or more arrays is mapped to a physical database file. Such mapping is a database administration task and requires no change to class/table definitions or application logic. Moreover, mapping can be done within a specific sparse array; you can map one range of values to one physical location while mapping another to another file, disk drive, or even to another database server. This makes it possible to reconfigure Caché applications (such as for scaling) with little effort.'
Monday, March 15, 2010
New media uselessness
I'm not a new media expert but even I know that…
- Calling an ad a 'welcome screen' is a pointless trickery. I understand you need to pay for content somehow, no need to sugarcoat it
- Sometimes, more media is bad: if there is an article that lists the top 10 cities to live, 14 most troubled real estate markets, 10 top moments in British TV history, etc, well, I take that as information. I can just read it, I don't need photos to go with it, or if there are photos, they should be optional. Making me scroll through 10 or 14 screens, each heavy on images but low on info, that will result in me simply leaving an otherwise potentially interesting article
So maybe the death of print is largely exaggerated.
Updating Cache from Excel
Excel (2007) is great as a quick database front end tool – reasonably versatile and easy to set up. This ease of use might make many want to be able to update a database from Excel, and that is not so easy.
It has to be done in code. One way would be through linking the Excel file to the database server (there are different mechanisms for doing this, e.g. OPENROWSET in SQL Server or the SQL Gateway in Cache). However, if you're running Office in 64-bit mode you soon discover that there is no 64-bit compliant Excel ODBC driver.
A quick and more natural solution is to embed the database update code in Excel itself; in the case of a Cache backend, there are two ways to write this code:
- Using ADO/ODBC
Dim cm As Command
Dim cn As Connection
Dim cns As String
cns = "DSN=CacheWeb User"
Set cn = New Connection
cn.Open cns
Set cm = New Command
cm.ActiveConnection = cn
cm.CommandType = adCmdText
cm.CommandText = "INSERT INTO Income(UserId, Income, Country) VALUES('@u', @i, '@c')"
cm.Execute
- Using Cache ActiveX
A bit more interesting since it gets into some Cache internals:
Dim Factory As CacheObject.Factory
Set Factory = New CacheObject.Factory
If Factory.Connect("cn_iptcp:127.0.0.1[1972]:TESTDBNS") = False Then
MsgBox "Failed to connect"
Exit Function
End If
Dim Income As Object
Set Income = Factory.New("Income")
Income.UserId = "2"
Income.Income = 120
Income.country = "PAK"
Income.sys_Save
Income.sys_Close
Set Income = Nothing
Saturday, March 13, 2010
HealthSpace
It seems there is a government-run GoogleHealth-like service in the UK.
I am still miffed by the resistance people show to this type of project. After all, they bank online. Why not keep track of their health info online?
I am still miffed by the resistance people show to this type of project. After all, they bank online. Why not keep track of their health info online?
Thursday, January 21, 2010
Google App Engine and Python
Quick steps to develop with Google App Engine:
- download the SDK
- this will place a Google App Launcher shortcut on your desktop
- click on it
- File > Create New Application and choose the directory (a subdirectory with the app name will be created there)
- Edit and change the name of the main *.py file you'll be using (say, myapp.py)
- create your myapp.py file and save it in the subdirectory created 2 steps ago
- select the app in the Google App Launcher main window and click Run
- open a browser: http://localhost:808x (this is the default value, check in your application settings as defined in Google App Launcher)
- then you have to deploy it to your applications in your Google profile
More, later, this is just a quick vade mecum.
- download the SDK
- this will place a Google App Launcher shortcut on your desktop
- click on it
- File > Create New Application and choose the directory (a subdirectory with the app name will be created there)
- Edit and change the name of the main *.py file you'll be using (say, myapp.py)
- create your myapp.py file and save it in the subdirectory created 2 steps ago
- select the app in the Google App Launcher main window and click Run
- open a browser: http://localhost:808x (this is the default value, check in your application settings as defined in Google App Launcher)
- then you have to deploy it to your applications in your Google profile
More, later, this is just a quick vade mecum.
Tuesday, January 19, 2010
MySQL errno 150
InnoDb needs an index to exist on the column referenced by a FKey. Interesting, I have to check if this is a requirement of the relational model, I don't remember seeing that before although I seem to recall that this might be one of those auto/hidden indexes created by SQL Server (__________ix#122200_____________, etc).
Monday, January 04, 2010
Interesting SQL
select * from #t1
can also be written as....
select * from #t1 t1 left join #t2 t2
on 1 = 2
While:
select * from #t1 t1 left join #t2 t2
on 1 = 1
... is really a cross join.
This is acceptable:
select * from
(select 1 a, 2 b, 3 c) t1
full outer join
(select 2 a, 4 b, 5 c) t2
on t1.a = t2.a
Perhaps not very useful, but interesting to know nonetheless as they are available. And, I really do like (T-SQL's new) MERGE statement.
can also be written as....
select * from #t1 t1 left join #t2 t2
on 1 = 2
While:
select * from #t1 t1 left join #t2 t2
on 1 = 1
... is really a cross join.
This is acceptable:
select * from
(select 1 a, 2 b, 3 c) t1
full outer join
(select 2 a, 4 b, 5 c) t2
on t1.a = t2.a
Perhaps not very useful, but interesting to know nonetheless as they are available. And, I really do like (T-SQL's new) MERGE statement.
Subscribe to:
Posts (Atom)




