A few ideas from an article by Microsoft's Roger Wolter on the MS infrastructure support for reliability in connected systems 9 (in MS Architecture Journal, vol 8):
- SOA = connected systems
- services communicate through well defined message formats => reliability = reliability of the communication infrastructure
- message handling between services more complex than client/server because server must make client decisions
- message infrastructures in the MS world: MSMQ, SQLS Broker, BizTalk (also offers data transformation)
- problems:
1. execution reliability (handling volume): different technologies deal with this differently, e.g. stored procedure 'activation' in Service Broker
2. lost message (communication reliability)
3. data reliability
Thursday, December 07, 2006
Monday, November 27, 2006
Quartz Composer
For the last few days I have been experimenting with Apple's Quartz Composer. While this is primarily a motion-design tool (and a very powerful one indeed), it is also an example of a very effective graphical programming environment. Prior to this, I had seen such tools in the Windows environment and was less than impressed, but QC is really amazingly powerful; you can parse structures, use variables, loops, and everything somehow fits together very well. I see uses for this metaphor in the BPEL world, at the very least, but the whole world of distributed computing seems a good fit for it.

By the way, this is the 'code' behind one of the rather phenomenal demos that can be found here.
Thursday, November 02, 2006
Web OS part II
To further illustrate the merging of Web, Database, and fileshare services, I'm currently involved in a Sharepoint installation process where data from users' file shares will be moved to the Sharepoint collaborative environment, with a SQL Server database as physical storage. Thus, the Internet replaces the file storage functionality, by delegating the actual storage to the SQL engine.
Saturday, October 21, 2006
MacOS run loops and console mode
Run loops do NOT run automatically in console mode, not even on the main thread. It kind of makes sense, run loops are one of the mechanisms that support GUI events. So you have to create a run loop manually when running in console mode; it can use multiple timers, and it will pre-empt the main thread, whose execution will only resume after the run loop's timers finish running.
Sunday, October 15, 2006
Adventures in multithreading
An insidious race condition arises in the following situation (which I encountered in Objective-C, but any language that passes by reference will allow for the same):
I have a consumer function which writes a message to a file or database and which can be called by multiple threads - so it is LOCKed. This function is called by threads generated by a loop, where the thread instantiation function takes as parameter a string which is modified by each loop iteration. E.g., in pseudo-C:
string msg;
for( i = 0; i < 10; i++ ){
fsprintf( msg, "parameter: %i", i );
launchThread( msg );
}
void launchThread( string parm ){
plock lock;
fprintf( fHandle, parm );
plock unlock;
}
Of course since the fprintf needs to be atomic (in order not to generate a bus error), it is the one that has to be locked. However, msg is a shared resource as well. If you run this code as it is you will get an output similar to the following:
parameter20
parameter20
parameter30
Instead of the expected:
parameter1
parameter2
parameter3
That is because msg is modified by the loop and by the time thread #x has picked it up, who knows what value it has - certainly not one in sync with #x.
The solution is to provide as parameter to the thread a full immutable copy of msg and not a reference to msg.
I have a consumer function which writes a message to a file or database and which can be called by multiple threads - so it is LOCKed. This function is called by threads generated by a loop, where the thread instantiation function takes as parameter a string which is modified by each loop iteration. E.g., in pseudo-C:
string msg;
for( i = 0; i < 10; i++ ){
fsprintf( msg, "parameter: %i", i );
launchThread( msg );
}
void launchThread( string parm ){
plock lock;
fprintf( fHandle, parm );
plock unlock;
}
Of course since the fprintf needs to be atomic (in order not to generate a bus error), it is the one that has to be locked. However, msg is a shared resource as well. If you run this code as it is you will get an output similar to the following:
parameter20
parameter20
parameter30
Instead of the expected:
parameter1
parameter2
parameter3
That is because msg is modified by the loop and by the time thread #x has picked it up, who knows what value it has - certainly not one in sync with #x.
The solution is to provide as parameter to the thread a full immutable copy of msg and not a reference to msg.
Monday, September 18, 2006
Again, GoogleMaps
..it seems it's an issue of latency. From a really fast connection it was able to recognize both Tokyo and Hong Kong. London is still un-geocodable though I am afraid.
Objective-C
I have recently started looking into Objective-C. In my experience, one of the biggest hurdles when learning C++ is understanding who does what; textbooks focus on OO and spend a lot of time on discussing buiding classes and coming up with silly examples, and little is said about how does this translate into executable code. With C you still have a pretty good idea how the code becomes machine code. With C++ the connection is broken; a class does not map to registries and you are left with a major gap in the continuum. The same problem (even to a larger extent) occurs with SQL or VM-type languages such as C#, Java, or Actionscript.
The ObjC instructions from Apple are the only ones I have seen so far that do a good job at explaining the runtime, and how OO constructs become procedural code. I am very impressed.
I have a first attempt at writing Mac OS X code here, a Cocoa front end to Unix queues. IPCS seems to not work with queues on Mac, but other than that the system calls seem to work quite well.
The ObjC instructions from Apple are the only ones I have seen so far that do a good job at explaining the runtime, and how OO constructs become procedural code. I am very impressed.
I have a first attempt at writing Mac OS X code here, a Cocoa front end to Unix queues. IPCS seems to not work with queues on Mac, but other than that the system calls seem to work quite well.
Friday, September 15, 2006
GoogleMaps v2
I finally rewrote the Maps application in a more objectified JavaScript. The source code is here and you can see it in action here. It seems that the Google Geocoder also does not recognize London, besides Hong Kong (actually, HK is sometimes recognized! what gives?) and Tokyo.
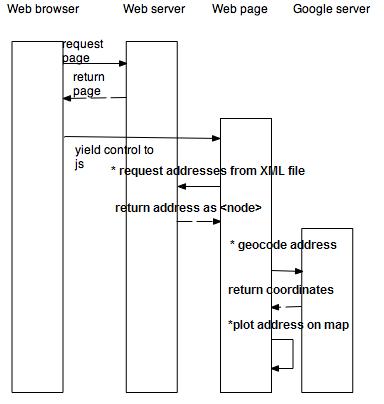
Flickr (FlickrMaps) uses it in a similar fashion.
Here is the UML Sequence Diagram of the interactions caused by this application:
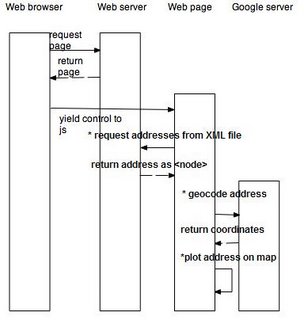
Flickr (FlickrMaps) uses it in a similar fashion.
Here is the UML Sequence Diagram of the interactions caused by this application:
Thursday, September 14, 2006
SQLite
...is very easy to use. To use from C (assuming gcc is the compiler):
- #include sqlite3.h
- compile like this: gcc -lsqlite3 file.c
- you really only need 3 API functions, sqlite3_open, sqlite3_exec, sqlite3_close
- for sqlite3_exec, you need to provide a callback that takes the number of columns, the name of each column, and the value of each column; the callback is called by the library for each component of the resultset
- you can create a database using 'sqlite3 database_name.db' from a shell prompt.
- #include sqlite3.h
- compile like this: gcc -lsqlite3 file.c
- you really only need 3 API functions, sqlite3_open, sqlite3_exec, sqlite3_close
- for sqlite3_exec, you need to provide a callback that takes the number of columns, the name of each column, and the value of each column; the callback is called by the library for each component of the resultset
- you can create a database using 'sqlite3 database_name.db' from a shell prompt.
Monday, August 28, 2006
GoogleMaps
Since I will soon have my 'summer' vacation, here is a link to my first GoogleMaps app: a list of places I have been to. It's a V1 thing, hampered by my inadequate JavaScript skills, that I promise to improve.
I'm kind of surprised though that the Google Geocoder does not seem to recognize (cities in) Japan and China?? I even tried their online demo and it cannot find these two locations.
The API is here.
I'm kind of surprised though that the Google Geocoder does not seem to recognize (cities in) Japan and China?? I even tried their online demo and it cannot find these two locations.
The API is here.
Of databases and connections
A few notes to self regarding SqlClient and OleDb connections:
Which reminds me, each OS should provide some kind of relational/transactional storage service. Unix/Linux/Mac OS already does - SQLite.
link between program and data
opening a connection is expensive
hence connection pooling: ADO does not destroy the connection object even after you close it
the connection is kept in a pool
it is destroyed after a time out interval (60 seconds => disconnect in SQL Trace)
reusable connection: which matches the connection details(data store, user name, password)
to turn connection pooling off in OLE DB: append to ConnectionString 'OLE DB SERVICES = -2':
significant differences: 6 seconds for 100 000 connections to ....?
not using this leaves the connection in SQL logged in at the time of the initial logon even after it is closed and reopened in code
the connection disappears from Activity Monitor when the program exits
however, if a connection is closed and the program is still running, after a while it disappears from the Activity Monitor (after the time out)
if the connection is not closed, it stays open in the Activity Monitor
multiple connections are opened if a Connection.Open is issued even if they have the same authentication and data store
setting the connection to null/Nothing clears it from the pool (? does not seem to affect the Activity Monitor)
if the connection is set to nothing without closing it, it shows in Activity Monitor
not closing the connection causes it not to time out even when set to nothing
it is not clear what effect has setting the connection to Nothing/Dispose-ing in OleDb
in ODBC: use the control panel (how do you turn it off???)
using the SqlClient instead of OleDb shows the application in Activity Monitor as .Net SqlClient Data Provider
using SqlClient seems to keep the connection alive even after closed for longer than OleDb (does it ever time out?)
using OleDb shows the application as the exe not the OleDb Data Provider
Which reminds me, each OS should provide some kind of relational/transactional storage service. Unix/Linux/Mac OS already does - SQLite.
Wednesday, August 23, 2006
Web Operating System?
Various web cognoscenti have been ballyhooing the 'OS' concept in a web context: Google OS. This has more to do with the coolness factor of any new software development arena than with actual functionality provided by the respective software.
The Google suite offers the following:
GoogleDesktop (supposedly at the core of the 'OS', and a resource hog to boot!)
Audacity (audio editing)
Orkut (social networking)
GoogleTalk
GoogleVideo
GoogleCalendar
Writely(word processing)
Gdrive (internet data storage)
Other than Gdrive, none of the above belong to an OS.
Leaving coolness aside, there are genuinely innovative Web-based applications whose complexity is close enough to that of desktop-based applications. For example, computadora.de 's shell is not that different from Windows 95's shell as far as the basic functionality it offers. Flash is a kind of Win32 in this case.
On the middle layer, salesforce.com is a good example of application domain functionality provided by a Web-based layer. It should be entirely possible to offer a payroll processing service.
And yes, I have a computadora.de account. You can even upload mp3's there and play them using the integrated mp3 player – which I did, an Alejandro Fernandes song, in keeping with the Mexican origin of the software.
SQL 2005 Endpoints
SQL Server can act as an application server by the means of endpoints (listeners). These can be defined over TCP or over HTTP, and support SOAP, TSQL, service broker, and database mirroring payloads.
To create a SOAP endpoint, create the stored procedures or functions that provide the functionality. Then run a CREATE ENDPOINT ... AS HTTP... FOR SOAP. Important parameters: SITE, and the WEBMETHODs collection.
A SOAP request returns an object array or a DataSet object. The default SOAP wrapper is created by Visual Studio.
This is quite nice. If you need to use a data-centric web service, just create one directly in SQL. To use it, just define the Web reference in the VS IDE; this will make an object of type SITE with a endpoint member you can access the data exposed by the SQL Server (e.g. If your SITE parameter was set to 'mySite', and the endpoint was named 'myEndPoint', you have a mySite object available which has a myEndPoint member, which exposes the functions/stored procedures defined on the SQL Server).
Monday, August 21, 2006
getUserPhotos part II
Zuardi in the previous post means Fabricio Zuardi, and he is the author of a Flickr API kit: a (REST-based) implementation of the Flickr API client in Actionscript. For some reason, he forgot/overlooked to implement one of the methods in the API, getUserPhotos.
Friday, August 18, 2006
Finally, getUserPhotos
I finally completed the missing flickr.urls.getUserPhotos from Zuardi’s Flickr library for Actionscript. It was easier than I though. Here it is:
public function getUserPhotos(api_key:String, user_id:String):Void{
var method_url:String = _rest_endpoint +
"?method=flickr.urls.getUserPhotos&api_key=";
var flickrUrlsObjPointer:FlickrUrls = this;
if(!api_key){
throw new Error("api_key is required");
}
else
this._api_key = api_key;
method_url += this._api_key;
if( user_id )
method_url += "&user id=" + user_id;
else
method_url += "&user_id=" + this._user_id;
this._response.onLoad = function(success:Boolean)
{
var error:String = "";
var isRsp:Boolean = false;
if( success )
{
if( this.firstChild.nodeName == "rsp" )
/* got a valid REST response */
{
isRsp = true;
if( this.firstChild.firstChild.nodeName == "user")
/* got a usable return */
{
flickrUrlsObjPointer._user_photos_url =
this.firstChild.firstChild.attributes['url'];
}// end usable
else
if(this.firstChild.firstChild.nodeName == "err")
/* got an error */
{
error ="ERROR CODE:" +
this.firstChild.firstChild.attributes['code'] +
"msg:" + this.firstChild.firstChild.attribute
['msg'];
}// end error
}/* end valid REST */
else
error = this.firstChild.attributes['code'] +
" msg: " + this.firstChild.attributes['msg'];
}// end Success
else
error = "Cannot load user photos: " +
method_url;
flickrUrlsObjPointer.onGetUserPhotos
(error,flickrUrlsObjPointer);
}//end onLoad
this._response.load( method_url );
}//end function
Some of his original coding is a bit grating to a perfectionist such as me :) However, I find the self reference (var flickrUrlsObjPointer:FlickrUrls ) that enables him to reach to the parent object in onLoad a nice touch. Actionscript 2 is still a mess though as far as readability.
For the unitiated, all we are trying to do is to capture the output from a REST call such as this: http://www.flickr.com/services/rest/?method=flickr.urls.getUserPhotos&api_key=404d98e10174604c8050f4f732e2162e&user_id=66489324%40N00
Via a XML object – the expected response is something like this
public function getUserPhotos(api_key:String, user_id:String):Void{
var method_url:String = _rest_endpoint +
"?method=flickr.urls.getUserPhotos&api_key=";
var flickrUrlsObjPointer:FlickrUrls = this;
if(!api_key){
throw new Error("api_key is required");
}
else
this._api_key = api_key;
method_url += this._api_key;
if( user_id )
method_url += "&user id=" + user_id;
else
method_url += "&user_id=" + this._user_id;
this._response.onLoad = function(success:Boolean)
{
var error:String = "";
var isRsp:Boolean = false;
if( success )
{
if( this.firstChild.nodeName == "rsp" )
/* got a valid REST response */
{
isRsp = true;
if( this.firstChild.firstChild.nodeName == "user")
/* got a usable return */
{
flickrUrlsObjPointer._user_photos_url =
this.firstChild.firstChild.attributes['url'];
}// end usable
else
if(this.firstChild.firstChild.nodeName == "err")
/* got an error */
{
error ="ERROR CODE:" +
this.firstChild.firstChild.attributes['code'] +
"msg:" + this.firstChild.firstChild.attribute
['msg'];
}// end error
}/* end valid REST */
else
error = this.firstChild.attributes['code'] +
" msg: " + this.firstChild.attributes['msg'];
}// end Success
else
error = "Cannot load user photos: " +
method_url;
flickrUrlsObjPointer.onGetUserPhotos
(error,flickrUrlsObjPointer);
}//end onLoad
this._response.load( method_url );
}//end function
Some of his original coding is a bit grating to a perfectionist such as me :) However, I find the self reference (var flickrUrlsObjPointer:FlickrUrls ) that enables him to reach to the parent object in onLoad a nice touch. Actionscript 2 is still a mess though as far as readability.
For the unitiated, all we are trying to do is to capture the output from a REST call such as this: http://www.flickr.com/services/rest/?method=flickr.urls.getUserPhotos&api_key=404d98e10174604c8050f4f732e2162e&user_id=66489324%40N00
Via a XML object – the expected response is something like this
user nsid = “66489324%40N00” url="http://www.flickr.com/photos/zzkj/”
Tuesday, August 15, 2006
I hate embedded Crystal
These last days I had the dubious pleasure of setting up an integrated Crystal Reports xi solution. Reporting is certainly one of the less glamorous but more crucial aspects of corporate computing. This was a simple RPT to PDF converter, yet the compiled distributable clocked in at a hefty 70 MB, mostly due to the dreaded merge modules (a 150+ MB separate download; at least they seem to have fixed the annoying KeyCode bug). Not to mention that in order to get it to work with Visual Studio 2005 I had to download a Release 2 – 2 downloads of 700 and 300 MB, respectively.
Clearly, this is unacceptable. MS Reporting Services all of a sudden makes sense although that is no walk in the park either.
Most of CR’s (now, Business Objects) heft comes from, I think, the fact that it covers the entire processing workflow – connecting to data, parsing the data streams, rendering the results. It connects to a dizzying array of data sources and it may have its own internal query processor for all I can tell. In fact, there would be a nice architectural solution to this if one considers that reporting is really just the basic processing of a firehose data stream. If vendors could come up with and agree on an ODBC-type of interface, the life of report tool creators (and of programmer users) would be so much easier. Everything that Crystal connects to today, for example, could be a data store supporting a ‘reporting’ interface. Querying the data store via this interface (if binary objects can describe their supported methods via IUnknown, certainly data can describe its own structure!) would result in a XML output that could be ideally be streamed directly to a XAML visual layer.
It would be nice.
Clearly, this is unacceptable. MS Reporting Services all of a sudden makes sense although that is no walk in the park either.
Most of CR’s (now, Business Objects) heft comes from, I think, the fact that it covers the entire processing workflow – connecting to data, parsing the data streams, rendering the results. It connects to a dizzying array of data sources and it may have its own internal query processor for all I can tell. In fact, there would be a nice architectural solution to this if one considers that reporting is really just the basic processing of a firehose data stream. If vendors could come up with and agree on an ODBC-type of interface, the life of report tool creators (and of programmer users) would be so much easier. Everything that Crystal connects to today, for example, could be a data store supporting a ‘reporting’ interface. Querying the data store via this interface (if binary objects can describe their supported methods via IUnknown, certainly data can describe its own structure!) would result in a XML output that could be ideally be streamed directly to a XAML visual layer.
It would be nice.
Wednesday, August 09, 2006
A web crawl algorithm
For a while now I have been very intrigued by web crawlers. After all it’s the stuff of hacker movies… So a few nights ago I came up with a nice little algorithm.
Starting with a given URL, we want to open the web page found at that URL, build the list of pages it references, and do the same for each page referenced therein. Of course, since this could potentially scan the entire www, I decided to limit the actual exploration to pages in the same domain (the other pages will be terminal nodes). And, I wanted to build an unordered list of references; so the first output would be a list of all the pages found this way, and the second a list of page pairs (unordered: if page A href’s page B and page B href’s page A, I wanted only one A,B pair to be shown).
It’s done like this: we start with two (empty) collections, one for the pages (indexed by the page’s link), the other for the page pairs (the first one is an object collection, the second, an object reference collection).
- builds a list of links in the document (this is the weak or rather inelegant point of the algorithm; I am using regular expressions to extract the links, and problems stem from the variety of ways in which a href can be coded in HTML: href=www, href=’www’, and there can be relative and absolute links);
- for each link, if the respective address exists in the object collection (remember, this collection is indexed by the (object) page’s link), add the pair (the current page, at this step, the root, and the page identified by the link) to the pairs collection (if: the link does not refer to the current node, to avoid self-referential links, and if the pair does not already exist in the reverse order);
- if the address does not exist, create a new page object, add it to the objects and to the links collection, and call this object’s discover method (unless the page points to a different domain, or to a non-readable object such as a jpeg).
Nice object recursion. Again, most of the code deals with reading the HTML stream, parsing the href’s, etc, the algorithm itself takes a mere 30 lines or so. I implemented it in .NET and after banging my head against the wall with a few limit cases, I got it to work very nicely, and a Java implementation would be just a transcription. I’ll look into porting it to Actionscript next.
Actually I could have used only one collection. Instead of inspecting the objects collection I could have inspected the pairs collection (after making it a full object collection). This would have been a more awkward and time consuming search, since each page object could be in that collection multiple times, whereas in the current object collection it is found only once.
I am not sure how else would you do a crawler (probably, the Google search index algorithm employs a similar crawling methodology) without being able to DIR the web server. Which raises the question: would a page that is never referenced by any other page ever be found by Google?
Here’s hoping this impresses Sandra Bullock (The net) or Angelina Jolie (Hackers).
Saturday, August 05, 2006
Thursday, July 27, 2006
XML-RPC and others
Looking at concepts related to mash-ups, inspired in part by Flickr and in part by Amazon’s Simple Queue Services. Have some notes here, and it’s a work in progress. Basically I am trying to understand how each protocol works, starting with REST as it is found in Zuardi’s Actionscript (REST-based) API for Flickr. Also looking at SOAP and XML-RPC, and SQS Query (used by Amazon) which indeed seems more alike to Flick’r REST than Amazon’s REST is.
Also looking at implementing each protocol in .NET and Java.
To summarize, for REST you use HTTP GET, for the others, POST. Effectively this means that in Actionscript you use XML.send in the first case and XML.sendAndLoad in the second. In .NET, request = (HttpWebRequest)WebRequest.Create(restEndpoint) with the default parameters in the first case, and WebRequest.Create with some parameters set differently in the second case.
There is an open source library that somewhat simplifies XML-RPC in Actionscript. The documentation is not there so I had to spend a couple of hours to get it to work!
For the methods that need authentication in Flickr, the process is just as involved as it is with SQS, but no X.509?
People really seem to like REST with Flickr as I have not found any XML-RPC implementations (I did not search too hard though).
In Java you have to use the URL and HttpURLConnection classes. And there are plenty of XML-RPC implementations in Java.
Tuesday, July 25, 2006
Amazon Simple Queuing Service
I was quite excited to read about Amazon’s Simple Queuing Services. It’s obviously a development based on their Storage Services, and it shows that:
- the commoditization of hitherto proprietary 'backend' services (perhaps under the influence of open source, and enabled by the likes of SOAP and REST). Queuing solutions such as RendezVous and MQSeries used to be complex beasts; no more. SQS has a few simple interfacing protocols, and while it may be lacking the more advanced features offered by the others, it does offer a solid (and cheap!) queuing/messaging platform;
- the internet is becoming a true execution ‘platform’, offering advanced runtime services. SQS is caller agnostic so any clients can use it – including those written in languages far removed from the ‘native’ OS, such as Actionscript or Python. It is entirely possible that a transaction broker or even DBMS web service be in the offering not too far in the future. I am curious to see how ‘mainstream’ web applications will take advantage of this. Large applications (including games or business systems) are now possible that can communicate asynchronously… the infrastructure is migrating from the OS to the web.
The security needs are quite involved and demand a HMAC-SHA1 hash function to work with the user's private key. Fortunately, Google has as API for both Win32 and Java that implements the HMAC-SHA1 funcaionality demanded by SQS.
Sunday, July 16, 2006
Image test

Other than a useless showoff of my Tibetan flag, the purpose of this photo was to test how images are rendered in Blogspot. I am tinkering with the Flickr API these days and was curious to see if I can do some distributed work between the Google domain (is it namespace?) and the Flickr one. Which reminds me of a few ideas that I read about the Internet as a programming platform. I really need to digest this a bit. The whole mashup concept, when the hype dies down, may have some actual value to it. Although the issue of trust seems paramount if it is to succeed; I do like the idea of throwing a request into a black hole and getting a response back, if I trust the black hole. Just getting started on a web services project and I do like the idea more and more. The difference being that in my case, we control the black hole – we being a B2B chain. I won’t talk much about it since it is a very new concept somewhat patented by my employer, but expect sometime in the near future to be able to shop for medical services the same way you currently shop for travel and books online.
Back to Internet apps, Web 2.0, et. al.: the Blogspot word processor is s-l-o-w on my laptop. And now we have online spreadsheets. That's cool, but do we really need it? And, has anyone thought of an online compiler - type your code in a www window and have it compiled behind the scenes? Let's web 2.0-enable web 2.0 development.
Not really related… I have been thinking about the concept of informatics quite a bit lately. I already mentioned that design (information design, motion design… basically, any kind of computerized visual design, for lack of a better term) is a major interest of mine (as a consumer/hobby-ist); and professionally too, since it is, after all, the visible end of the software development stack and the one that is the most removed from the ld hl, 0x0000 level. When I was growing up, informatics meant a heavily math-based science of algorithms and it was truly intimidating. Today it seems to take almost New Age-y overtones. Great. We have artists, we have ‘communists’ (open source movement), who says the world of software is boring?
More on the Flash IDE
It just seems that I am spending a lot of time in Actionscript these days. I’m working on my Googlepages home page and integrating it with Flash has been a headache.
I just read in Flashmagazine a feature about the Flash platform and its possible future evolution. One additional gripe to those I already listed that they mention is the long compile times. Having spent a Saturday largely waiting for a smallish Actionscript app to compile (okay I did compile repeatedly!), I do agree – this is annoying.
They do talk about XAML and its possible effect on the Flash market share. Quite correctly they point out that XAML is restricted to the Microsoft world at the moment.
The Eclipse environment seems to be the savior for Flash, other than initiatives such as FlashDev. I am not so sure – I am just not crazy about Eclipse or other Java-based IDE’s. They are just slow when compared to a native IDE, just like the .NET-based SQL Server 2005 Enterprise Manager is slow when compared to the previous EM’s.
Adobe has a hard fight ahead. It must not antagonize its core design audience while attempting to make Flash a real development environment. As an animation tool Flash is great, but animations will still be a niche. I really should be going back to Flex for my future Actionscript programming needs… now that it has finally been released.
I just read in Flashmagazine a feature about the Flash platform and its possible future evolution. One additional gripe to those I already listed that they mention is the long compile times. Having spent a Saturday largely waiting for a smallish Actionscript app to compile (okay I did compile repeatedly!), I do agree – this is annoying.
They do talk about XAML and its possible effect on the Flash market share. Quite correctly they point out that XAML is restricted to the Microsoft world at the moment.
The Eclipse environment seems to be the savior for Flash, other than initiatives such as FlashDev. I am not so sure – I am just not crazy about Eclipse or other Java-based IDE’s. They are just slow when compared to a native IDE, just like the .NET-based SQL Server 2005 Enterprise Manager is slow when compared to the previous EM’s.
Adobe has a hard fight ahead. It must not antagonize its core design audience while attempting to make Flash a real development environment. As an animation tool Flash is great, but animations will still be a niche. I really should be going back to Flex for my future Actionscript programming needs… now that it has finally been released.
Monday, July 10, 2006
Where is it all going
All this recent work in ActionScript has got me thinking: where does Flash fit anymore?
The evolution of Flash has clearly been in the direction of a fully fledged programming language. I.e., increased complexity. It is not your ‘average’ designer’s tool anymore – without any disrespect to the design community, for which, as an avid consumer of design, I have a lot of respect. Flash still has a way to go to be a complete programming language (support for multithreading, direct O/S access for example), but at that point will it have lost its unique design orientation, and will it become just another dev kit? Can it compete to the .NET/Java/perhaps Ruby on Rails worlds on its own merits as a software development tool if it sheds its design (web, motion) orientation?
But even if it stays primarily a design tool: can it compete with the likes of MS Expression? Platform loyalties aside, Expression and XAML provide an extension into the interactive arena of a formidable development stack.
That Flash poses some problems to developers (which can be quite annoying in large projects especially, but large projects are what make a development environment a ‘serious’ tool) has been evident by the emergence of Laszlo and even Flex; Flash still remains powerful as a runtime rendering engine with unmatched ubiquity. However, I see the former as yet untested, and the latter as liable to come under attack from XAML. It will be interesting to see which direction Adobe wants to take it in, and I am waiting for more details about their Apollo initiative.
The ‘distributed software’ ecosystem would be something like this:
Systems: C/C++ code, platform specific. Software engineers’ domain. Includes apps such as databases.
‘Piping’: most everything else. Business rules-systems. .NET, Java, PHP, Ruby, Python. Software architects’ domain. Some unmanaged/systems-level coding.
Front end: Flash, XAML, Looking Glass (?). Designers’ domain. Behavior coding, interfacing, front end logic, mash-ups, consuming web services.
Saturday, July 08, 2006
ActionScript annoyances
Contrary to what many hardcore developers may think, I do find ActionScript (and its brethren - JavaScript & family) a powerful language. Especially when embedded in Flash, it can do a lot of neat stuff. However, it has some problems for more complex development tasks: visibility (the layers are a pain, and especially in anonymous functions visibility can get tricky), typing, and multithreading (important because some operations are asynchronous which in fact creates a second thread). Finally, the interspersing of code in the FLA file is a readability/maintainability disaster, and thankfully Macromedia addressed this by enabling external class definitions that extend MovieClip or UIObject. The debugger and IntelliSense are both a bit of a joke too...
All of the above are neatly summarized in this: I have an object that has a XML object member. XML.load( file.xml ) is an asynchronous operation and the only way I could find to notify the parent that XML has finished loading the file is by creating an object derived from XML that has a property pointing back to the parent so that it can callback the parent when it has finished. Here it is:
The 'parent' object:
class ActionMenu extends MovieClip {
private var oFile:XMLD;
/*
* constructor
*/
public function ActionMenu( xmlFile:String ){
oFile = new XMLD(this);
}//endCtor
/*
* CallbackLoad
* called by the XML object when it finished loading
* the document
*/
public function CallbackLoad(success:Boolean):Void{
if(success){
//...do whatever needs to be done
// XMLD implements XML's interface so use it as you
// would use a XML object
}else{
trace( "File not loaded!");
}//endIfElse
}//endCallbackLoad
}//endClass
The XML-derived object:
/*
* XMLD
* Used to notify Parent (ActionMenu) when the XML document is loaded
*/
class XMLD extends XML{
private var ptrAM:ActionMenu;
public function XMLD( p:ActionMenu ){
ptrAM = p;
this.onLoad = function(success:Boolean){
ptrAM.CallbackLoad(success);
}
}
}
All of the above are neatly summarized in this: I have an object that has a XML object member. XML.load( file.xml ) is an asynchronous operation and the only way I could find to notify the parent that XML has finished loading the file is by creating an object derived from XML that has a property pointing back to the parent so that it can callback the parent when it has finished. Here it is:
The 'parent' object:
class ActionMenu extends MovieClip {
private var oFile:XMLD;
/*
* constructor
*/
public function ActionMenu( xmlFile:String ){
oFile = new XMLD(this);
}//endCtor
/*
* CallbackLoad
* called by the XML object when it finished loading
* the document
*/
public function CallbackLoad(success:Boolean):Void{
if(success){
//...do whatever needs to be done
// XMLD implements XML's interface so use it as you
// would use a XML object
}else{
trace( "File not loaded!");
}//endIfElse
}//endCallbackLoad
}//endClass
The XML-derived object:
/*
* XMLD
* Used to notify Parent (ActionMenu) when the XML document is loaded
*/
class XMLD extends XML{
private var ptrAM:ActionMenu;
public function XMLD( p:ActionMenu ){
ptrAM = p;
this.onLoad = function(success:Boolean){
ptrAM.CallbackLoad(success);
}
}
}
Friday, June 23, 2006
beginHere();
There are already a lot of blogs on the web, millions I think. This one will be a place for me to jot down my opinions/thoughts/discoveries regarding a few topics of interest: large distributed computing systems, which often times are business information systems, and often, but not always, are internet-based systems. I'm interested in topics such as:
- database systems as programming environments and execution platforms: there is a lot of overlapping in functionality between what an OS does and what a DBMS does - journaling, page allocations, extent management, caching. Will these two converge, WinFS and SQL? I am really curious to see if at some point in the future DBMS will be just a standard service of the OS.
- as far as specific platforms, my interests cover the usual suspects, SQL Server, Sybase, Oracle, and more exotic offerings such as Intersystems Cache. Still trying to decide if MySQL is just a glorified Access!
- new generation web programming languages: especially those features that allow for distributed transactions and communication protocols
- clearly, we are seeing a differentiation of languages in those that support low level nuts and bolts systems programming (C/C++), and higher level languages that are used for interconnecting systems: C# 2.0, VB.NET, Java 5.0, ActionScript 3
- at an even higher level we are seeing presentation layer languages such as XAML and MXML... interesting Java begat C# and MXML begat XAML. Unless ideas spring independently in the noosphere!
- transaction processing systems and communication protocols: MTS, Tibco Rendezvous, Indigo... not sure if anyone uses DCOM/COM+ anymore? How about CORBA?
Subscribe to:
Comments (Atom)





